지난주에 이어 머신러닝에 대해 공부했다.
이번 주는 머신러닝의 한 분야인 딥러닝에 대해서 자세히 알아보았다.
딥러닝 (Deep Learning)
- 머신러닝의 한 종류, 선형과 비선형의 조합을 사영하여 추상화(Abstractions)를 시도하는 기계학습 알고리즘의 집합
- 사람의 사고방식을 기계에게 학습시키는 기계학습 분야 중 하나
- 인공 신경망에서 얻은 데이터를 사용하여 해당 데이터에 대한 규칙을 학습한다.
- 입력된 데이터가 연속된 층(Layer)에서 필터(Filter)를 거치면서 해당 데이터에 대한 학습을 하고 출력하는 것
- 이미지 분류, 세분화 및 인식 등과 같은 작업을 처리할 때 사용된다.

다음은 OR과 AND에 대한 그래프이다.

해당 그래프를 보면 알 수 있듯이 선형 회귀로는 OR과 AND 문제를 잘 해결했으며, 해당 모양을 가진 퍼셉트론(Perceptron)이라는 것이 나왔다.
우선 시작하기 전 퍼셉트론에 들어가는 값들에 대해서 알아보자
임계치 (θ : Threshold) : 어떤 값이 활성화되는 최소값
가중치 (w : Weight) : 각각의 입력 신호에 부여되는 값
편향 (Bias) : 학습 데이터가 가중치와 계산되어 넘어야 하는 임계점
- 편향값이 높으면 분류 기준이 엄격해지지만, 모델이 간단해지고 과소적합(Underfitting)이 발생할 수 있다.
- 편향값이 낮으면 데이터의 허용 범위가 넓어지지만, 모델이 복잡해지고 과적합(Overfitting)이 발생할 수 있다.
해당 과소적합(Underfitting)과 과적합(Overfitting)에 대해서는 밑에서 다뤄보도록 하겠다.
이제 퍼셉트론에 대해 알아보자.
퍼셉트론 (Perceptron)
- 가장 초기의 인공 신경망
- OR, AND 등의 게이트를 사용하여 해당 문제를 해결하는 데 사용
- 다수의 입력으로부터 하나의 결과를 출력하는 것
Input Layer : 입력값(x)
Weight : 가중치(w)
Output Layer : 출력값(y)

해당 퍼셉트론을 가지고 선형 회귀를 이루며 OR과 AND의 문제를 잘 해결하게 되었지만, 해당 문제들을 조합한 XOR 문제에 대해서는 해결할 수 있는 방법이 당장 존재하지 않았다.
그래서 XOR 문제를 해결하고자 많은 사람들이 시도하여 XOR 문제를 해결할 수 있는 다층 퍼셉트론(MLP : Multilayer Perceptrons)이 등장하였다.
다층 퍼셉트론 (MLP : Multilayer Perceptrons)
- OR, AND 등의 게이트를 조합하여 XOR 게이트 문제를 해결하고자 사용
- 하지만 MLP가 막 도입되던 시절에는 기술력의 한계로 인해 해당 개념을 실제로 행하는데 불가능했었다.
Input Layer : 입력값(x)
Hidden Layer : 은닉층
Output Layer : 출력값(y)

1969년도에 해당 MLP을 사용하지 못하자 당시 기술력으로는 불가능에 가깝다고 주장하여 많은 사람들이 문제를 포기하게 되었고, 딥러닝의 발전은 해당 시기에 그치게 되었습니다..
만!
1974년도에 발표된 역전파(Backpropagation)의 발표로 인해 딥러닝의 발전은 다시 불붙게 되었습니다.
역전파 (Backpropagation)
- XOR 게이트 문제를 해결하고자 했던 MLP를 풀고자 만들어진 알고리즘
- MLP에서 만들어낸 출력이 정답값과 다를 경우 가중치(w)와 편향값(Bias)을 조절하는 방법
- 출력에서 오차(Error)가 발견되면 점차적으로 조절하는 방법이다. (뒤 → 앞)

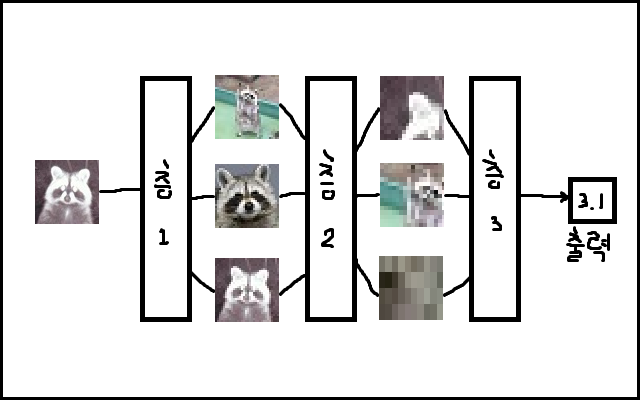
다음은 딥러닝에서의 네트워크 구조입니다.
딥러닝에서의 네트워크 구조는 사진과 같이 3가지로 나뉩니다.

Input Layer (입력층) : 네트워크의 입력 부분, 학습시키고자 하는 값(x)
Output Layer (출력층) : 네트워크의 출력 부분, 예측한 값(y)
Hidden Layer (은닉층) : 입력층과 출력층을 제외한 중간층
해당 구조에서 은닉층은 보통 중간 부분을 넓게 만드는 경우가 많고, 노드의 개수가 늘어나다가 줄어드는 방식으로 구성됩니다.
우리가 많은 시간을 투자하여 적당한 연산량과 정확도를 가진 딥러닝 모델을 만들었을 때, 해당 구조를 지닌 딥러닝 모델을 베이스라인 모델(Baseline Model)이라고 한다.
이러한 베이스라인 모델을 가지고 성능을 테스트하기 위해서는 해당 모델의 너비와 깊이를 조절하면서 과적합과 과소적합을 피하게끔 시간을 투자합니다.
너비 : 은닉층의 노드 개수를 늘린다.
깊이 : 은닉층의 개수를 늘린다.
너비와 깊이 : 너비와 깊이를 합쳐서 사용한다.
다음은 딥러닝에서의 주요 개념들이다.
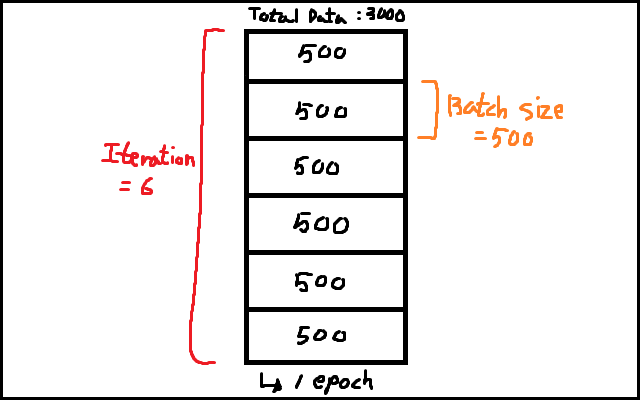
Batch와 Iteration, Epoch
Batch : 많은 양의 데이터셋을 학습하기 위해 작은 단위로 쪼개는 것
Iteration : 데이터셋의 Batch 값에서 전체 데이터셋을 학습할 때까지 반복하는 과정
Epoch : 머신러닝에서 반복 학습을 하는 단위
다음은 활성화 함수(Activation Functions)에 대한 설명이다.
활성화 함수 (Activation Functions)
- 서로 연결되어 있는 뉴런들은 전기 신호의 크기가 특정 임계치(Threshold)를 넘어야만 다음 뉴런으로 신호를 전달되도록 설계되어 있는데, 이러한 뉴런의 신호전달 체계를 보고 전기 신호의 임계치를 넘기면 다음 뉴런이 활성화되는 것을 활성화 함수라고 한다.
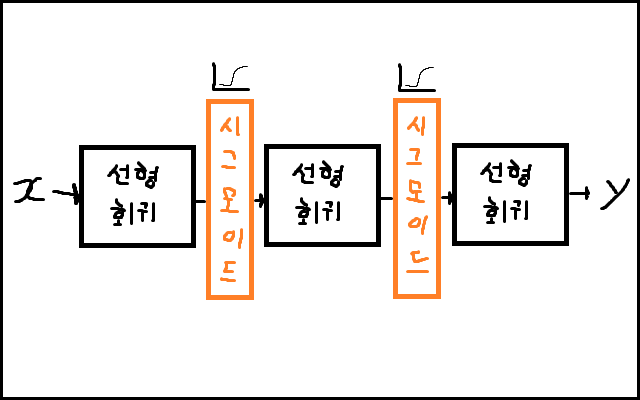
- 활성화 함수는 비선형 함수를 사용해야 하는데, 대표적인 비선형 함수로는 Sigmoid Function이 있다.
- 딥러닝에서는 비선형 함수를 사용하기 때문에 비선형 함수 자리에 Sigmoid Function을 넣으면 다음과 같은 모습이 된다.
해당 활성화 함수의 종류로는 Sigmoid, tanh, ReLU, Leaky ReLU, Maxout, ELU가 있다.
보통은 ReLU를 많이 사용하는데, ReLU는 학습이 빠르고 연산 비용이 적으면서 구현이 간단하다는 장점이 있기 때문이다. (ReLU : 0보다 작으면 0, 0보다 크면 그대로 출력)
다음은 퍼셉트론에서 먼저 나왔었던 과적합(Overfitting)과 과소적합(Underfitting)에 대한 것과 Best Fit에 대해 알아보자.
과적합 (Overfitting) : Training Loss는 낮아지는데 Validation Loss가 높아지는 현상
과소적합 (Underfitting) : 단순화로 인한 모델의 복잡도가 낮아지면 발생하는 현상
Best Fit : Test Error가 가장 낮은 점
딥러닝 모델을 설계하고 튜닝하면서 학습시키다 보면 가끔씩 Training Loss는 낮아지고 Validation Loss가 높아지는 시점이 있는데, 해당 현상을 그래프로 나타내면 다음과 같다.

그렇기에 우리는 적당한 복잡도를 가진 모델을 찾기 위해서 많은 시간을 투자해 최적합(Best Fit)에 가까운 모델을 만들어야 한다.
다음은 딥러닝의 주요 스킬들에 대해 알아보자.
데이터 증강 기법 (Data Augmentation)
- 과적합을 해결하기 위한 가장 좋은 방법은 데이터의 개수를 늘리는 것이지만 데이터가 부족할 경우가 다분한데, 해당 데이터를 보충하기 위해 사용하는 기법이다.
- 딥러닝에서는 주로 이미지 처리 분야에서 많이 사용한다.
- 이미지에 대해서 사람이 보는 것과 똑같이 딥러닝 모델에게 학습시키도록 한다.

드롭아웃 (Dropout)
- 과적합을 해결하기 위한 가장 간단하고 쉬운 방법, 과도하게 많이 생성된 노드들이 이어진 선을 제거하는 기법
- 각 배치마다 랜덤한 노드를 끊는데, 다음 노드로 전달할 때 랜덤 하게 출력을 0으로 만든다.

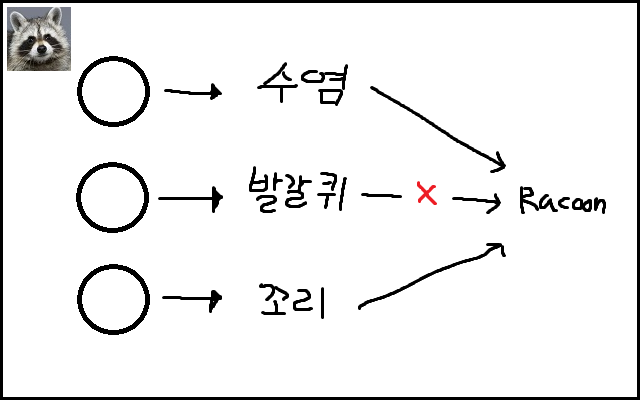
앙상블 (Ensemble)
- 여러 개의 딥러닝 모델을 만들어 각각 학습시킨 뒤 각 모델에서 나온 출력을 기반으로 투표를 하는 기법
- 머신러닝의 모델 중 Random forest와 비슷한 방식을 지녔다.
- 투표(Majority Voting)를 하거나, 평균값을 구하거나, 마지막에 결정하는 레이어(Layer)를 붙이는 등의 다양한 방법으로 응용이 가능하다.

Learning Rate Decay (=Learning Rate Schedules)
- 실무에서 자주 사용되는 기법으로, Local Minimum에 빠르게 도달하고자 할 때 사용한다.
- 학습의 앞부분에서는 큰 폭으로 움직이고, 뒷부분으로 갈수록 조금씩 움직여서 효율적으로 Local Minimum을 찾을 수 있도록 한다.

-
오늘은 주로 머신러닝에 속한 딥러닝에 대해서 알아보았다.
머신러닝에서 딥러닝이 많이 사용된다고 들었다.
그래서 그런지 딥러닝에 대한 강의가 시작되었을 때 어느 때보다 열심히 공부한 것 같다.
중요하다고 생각되는 것이었기에 개념들에 대해 열심히 공부하고 알아봤다.
많이 어렵기도 하고, '아 그렇구나!!'하고 팍 꽂히는 느낌의 그런 것이 없어서 공부하는데 많은 시간을 투자했다.
열심히 공부한 지식을 까먹지 말고 복습하는 느낌으로 적어서 그런지 더 뿌듯했던 것 같다.
:D
'TIL 및 WIL > TIL (Today I Learned)' 카테고리의 다른 글
| [TIL] 2022.05.18 (인스타 UI 복습, 사물인식 머신러닝 - 팀 프로젝트0) (0) | 2022.05.18 |
|---|---|
| [TIL] 2022.05.17 (Machine Learning, 머신러닝3) (1) | 2022.05.17 |
| [TIL] 2022.05.13 (Machine Learning, 머신러닝1) (0) | 2022.05.13 |
| [TIL] 2022.05.12 (Git-Github, 머신러닝0) (0) | 2022.05.12 |
| [TIL] 2022.05.11 (인스타 UI 클론 코딩 - 팀 프로젝트(끝)) (0) | 2022.05.11 |



